Inhalt
- Definition - Was bedeutet Web Crawler?
- Eine Einführung in Microsoft Azure und die Microsoft Cloud | In diesem Handbuch erfahren Sie, worum es beim Cloud-Computing geht und wie Microsoft Azure Sie bei der Migration und Ausführung Ihres Unternehmens aus der Cloud unterstützen kann.
- Techopedia erklärt den Web Crawler
Definition - Was bedeutet Web Crawler?
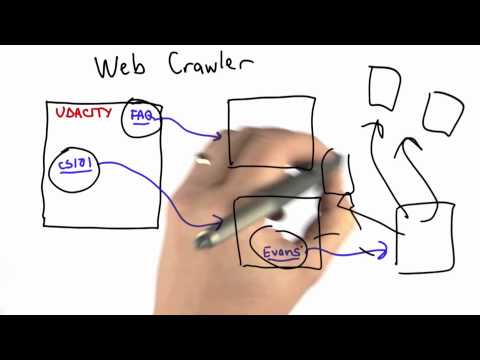
Ein Web-Crawler ist ein Internet-Bot, der bei der Web-Indizierung hilft. Sie durchsuchen eine Website seitenweise, bis alle Seiten indiziert wurden. Webcrawler helfen beim Sammeln von Informationen zu einer Website und den damit verbundenen Links sowie beim Überprüfen des HTML-Codes und der Hyperlinks.
Ein Web-Crawler wird auch als Web-Spider, automatischer Indexer oder einfacher Crawler bezeichnet.
Eine Einführung in Microsoft Azure und die Microsoft Cloud | In diesem Handbuch erfahren Sie, worum es beim Cloud-Computing geht und wie Microsoft Azure Sie bei der Migration und Ausführung Ihres Unternehmens aus der Cloud unterstützen kann.
Techopedia erklärt den Web Crawler
Web-Crawler erfassen Informationen wie die URL der Website, die Meta-Tag-Informationen, den Webseiteninhalt, die Links auf der Webseite und die von diesen Links ausgehenden Ziele, den Titel der Webseite und andere relevante Informationen. Sie verfolgen die bereits heruntergeladenen URLs, um zu vermeiden, dass dieselbe Seite erneut heruntergeladen wird. Eine Kombination von Richtlinien, wie z. B. Wiederholungsrichtlinie, Auswahlrichtlinie, Parallelisierungsrichtlinie und Höflichkeitsrichtlinie, bestimmt das Verhalten des Webcrawlers. Webcrawler stehen vor zahlreichen Herausforderungen, darunter das sich ständig weiterentwickelnde World Wide Web, Kompromisse bei der Auswahl von Inhalten, soziale Verpflichtungen und der Umgang mit Gegnern.
Webcrawler sind die Schlüsselkomponenten von Websuchmaschinen und -systemen, die Webseiten untersuchen. Sie helfen bei der Indizierung der Webeinträge und ermöglichen Benutzern das Abfragen des Index sowie das Bereitstellen der Webseiten, die den Abfragen entsprechen. Eine andere Verwendung von Web-Crawlern ist die Web-Archivierung, bei der große Mengen von Webseiten regelmäßig erfasst und archiviert werden. Webcrawler werden auch beim Data Mining verwendet, bei dem Seiten auf unterschiedliche Eigenschaften wie Statistiken analysiert und anschließend Datenanalysen durchgeführt werden.